Algorithms¶
We describe the various components of modern alchemical free energy calculations with YANK.
Solvent treatment¶
YANK provides the capability for performing alchemical free energy calculations in both explicit solvent (where a water model such as TIP3P [1] or TIP4P-Ew [2] is used to fill the simulation box with solvent) and implicit solvent (where a continuum representation of the solvent is used to reduce calculation times at the cost of some accuracy). While explicit solvent free energy calculations are still considered the “gold standard” in terms of accuracy, implicit solvent free energy calculations may offer a very rapid way to compute approximate binding free energies while still incorporating some of the entropic and enthalpic contributions to binding.
Implicit solvent¶
YANK provides the somewhat unique ability to perform alchemical free energy calculations in implicit solvent.
Solvent Models¶
For the implicit solvent models in YANK any of the AMBER implicit solvent models available in OpenMM are available for use in the implicit_solvent directive:
| Value | Meaning |
|---|---|
| {Not Set} | No implicit solvent is used when the option is not set. |
HCT |
Hawkins-Cramer-Truhlar GBSA model[3] (corresponds to igb=1 in AMBER) |
OBC1 |
Onufriev-Bashford-Case GBSA model[4] using the GBOBCI parameters (corresponds to igb=2 in AMBER). |
OBC2 |
Onufriev-Bashford-Case GBSA model[4] using the GBOBCII parameters (corresponds to igb=5 in AMBER). |
GBn |
GBn solvation model[5] (corresponds to igb=7 in AMBER). |
GBn2 |
GBn2 solvation model[6] (corresponds to igb=8 in AMBER). |
Generalized GBSA Model¶
In order to permit alchemical free energy calculations to be carried out in implicit solvent, the contribution of atoms in the alchemically annihilated region must also be annihilated. This is done by introducing a dependence on the alchemical parameter \(\lambda\) into the GBSA potential terms. Each particle i has an associated indicator function \(\eta_i\) which assumes the value of 1 if the particle is part of the alchemical region and 0 otherwise.
The modified Generalized Born contribution to the potential energy is given by [4]
where the indices i and j run over all particles, \(\epsilon_\text{solute}\) and \(\epsilon_\text{solvent}\) are the dielectric constants of the solute and solvent respectively, \(q_i\) is the charge of particle i, and \(||x_i - x_j||_2\) is the distance between particles i and j which we will short-hand to \(d_{ij}\) The electrostatic constant \(V_e\) is equal to 138.935485 nm kJ/mol/e2.
The alchemical attenuation function \(s_{ij}(\lambda, \eta)\) attenuates interactions involving softcore atoms, and is given by
The alchemically-modified GB effective interaction distance function \(f_\text{GB}(d_{ij}, R_i, R_j; \lambda, \eta)\), which has units of distance, is defined as
\(R_i\) is the Born radius of particle i, which calculated as
where \(\alpha\), \(\beta\), and \(\gamma\) are the tunable parameters for the solvent model. Exact values are discussed in later sections. \(\rho_i\) is the adjusted atomic radius of particle i, which is calculated from the atomic radius \(r_i\) as \(\rho_i = r_i-o_f\) where \(o_f = 0.009\) nm is the offset parameter. \(\Psi_i\) is calculated as an integral over the van der Waals spheres of all particles outside particle i:
where \(\theta\)(r) is a step function that excludes the interior of particle i from the integral. This integral can be re-written as sum over all other j particles in the system as
with
where \(U_p\) and \(L\) are the smoothed upper and lower bounds of \(\Psi\), \(S_j\) is the scalar factor on particle j from the HTC model which is a function of atom-type [3], and \(H(x)\) is the Heaviside step function following \(H(0)=1\).
The self-interaction energy of the particle is computed as
The alchemically-modified surface area potential term is a modified form of the term given by [7][8]
where \(\epsilon_{SA}\) is the surface area energy penalty and \(r_\text{solvent}\) is the solvent radius, which is taken to be 0.14 nm. The default value for the surface area penalty \(\epsilon_{SA}\) is 2.25936 kJ/mol/nm2.
HCT Solvent Models¶
The HCT model is actually a precursor to the generalized GBSA model as shown above. Instead of rewritting the
full equations, we can derive this model from the previous equations by changing the \(R_i\) equation to
OBCX Solvent Models¶
Note
OBC2 is the recommended model for implicit solvent in YANK
The OBC1 and OBC2 models follow the theory from the Generalized GBSA model and use the following parameters
for \(\alpha\), \(\beta\), and \(\gamma\):
OBC1: GBOBCI parameters \(\alpha\) = 0.8, \(\beta\) = 0, \(\gamma\) = 2.91.OBC2: GBOBCII parameters \(\alpha\) = 1, \(\beta\) = 0.8, \(\gamma\) = 4.85.
GBn Solvent Models¶
The GBn models are extensions to the generalized model above to correct for short range interactions when
\({d}_{ij} < R_i + R_2 + 2R_W\) where \(R_W\) is the radius of the solvent particle we are representing as
a continuum. These models can be computed through a small correction on the generalized model’s \(\Psi_i\) parameter
of
where \(m_0\) and \(d_0\) are parameters to maximize the term and have continuous derivatives, found numerically and tabulated internally. The \(S_{\text{neck}}\) parameter is tunable.
The GBn model refits \(\alpha\), \(\beta\), \(\gamma\) and all of the \(S_x\) terms for the following:
- \(\alpha\) = 1.095, \(\beta\) = 1.908, \(\gamma\) = 2.508.
- \(S_{\text{neck}} = 0.362\), \(S_H =1.091\), \(S_C = 0.484\), \(S_N = 0.700\), \(S_O = 1.068\)
The GBn2 model refits \(\alpha\), \(\beta\), \(\gamma\) per atomic scaling factor \(S_x\), and then
also refits the \(S_{\text{neck}}\) and \(o_f\) parameters for a total of 18 parameters. We do not show the
table here for space, please see Table 2 in Nguyen et al for the entries [6].
Explicit solvent¶
Solvent model¶
Any explicit solvent model that can be constructed via AmberTools is supported for building through the
pipeline module.
| Model | Water Model |
|---|---|
tip3p |
TIP3P water model [1] (older model used in many legacy calculations) |
tip4pew |
TIP4P-Ew water model [2] (recommended, default) |
tip3pfb |
TIP3P-FB water model [9] |
tip4pfb |
TIP4P-FB water model [9] |
tip5p |
TIP5P water model [10] |
spce |
SPC/E water model [11] |
swm4ndp |
SWM4-NDP water model [12] |
Electrostatics treatment¶
OpenMM supports several electrostatics models for the periodic simulation boxes used with explicit solvent calculations, all of which are accessible in YANK:
PME- Particle mesh Ewald (PME) [13][14] is the “gold standard” for accurate long-range treatment of electrostatics in periodic solvated systems.CutoffPeriodic- Reaction field electrostatics [15] is a faster, less accurate methods for treating electrostatics in solvated systems that assumes a uniform dielectric outside the nonbonded cutoff distance.Warning
YANK currently has some difficulty with alchemical transformations involving Reaction Field because of the inability to represent the long range contribution of the alchemically modified ligand over all alchemical states, so phase space overlap with the endpoints can be poorer than with other methods.
Ewald- Ewald electrostatics, which is approximated by the much fasterPMEmethod. It is not recommended that users employ this method for alchemical free energy calculations due to the speed of this method and availability ofPME.
Long-range dispersion corrections¶
Analytical isotropic long-range dispersion correction¶
Simulations in explicit solvent will by default add an analytical isotropic long-range dispersion correction to correct for the truncation of the nonbonded potential at the cutoff. Without this correction, significant artifacts in solvent density and other physical properties can occur [16].
Anisotropic long-range dispersion correction¶
Because this correction assumes that the solvent is isotropic outside of the nonbonded cutoff, however, significant errors in computed binding free energies are possible (up to several kcal/mol for absolute binding free energies of large ligands) if the diameter of the protein is larger than the nonbonded cutoff due to the significant difference in density between protein and solvent [16].
To correct for this, we utilize the anisotropic long-range dispersion correction described in Ref. [16]
in which the endpoints of each alchemical leg of the free energy calculation are perturbed to a system where the cutoffs
are enlarged to a point where this error is negligible.
Because this contribution is only accumulated when configurations are written to disk, the additional computational
overhead is small.
The largest allowable cutoff (slightly smaller than one-half the smallest box edge) is automatically selected for this
purpose, if the user does not specify one. Settings for this can be found in the
YAML options, or through the API at
yank.AlchemicalPhase.create()
Restraints and standard state correction¶
Restraints between receptor and ligand are used for two purposes:
- Defining the bound species: The theoretical framework for alchemical free energy calculations requires that the bound receptor-ligand complex be defined in some way. While this can be done by an indicator function that assumes the value of unity of the receptor and ligand are bound otherwise, it is difficult to restrict the bound complex integral to this region within the context of a molecular dynamics simulation. Instead, a fuzzy indicator function that can assume continuous values is equivalent to imposing a restraint that restricts the ligand to be near the receptor to define the bound complex and restrict the configuration integral.
- Reducing accessible ligand conformations during intermediate alchemical states: Another function of restraints is to restrict the region of conformation space that must be integrated in the majority of the alchemical states, speeding convergence. For example, orientational restraints greatly restrict the number of orientations or binding modes the ligand must visit during intermediate alchemical states, greatly accelerating convergence. On the other hand, if multiple orientations are relevant but cannot be sampled during the imposition of additional restraints, this can cause the resulting free energy estimate to be heavily biased.
In principle, both types of restraints would be used in tandem: One restraint would define the bound complex, while another restraint would be turned to reduce the amount of sampling required to evaluate alchemical free energy differences. In the current version of YANK, only one restraint can be used at a time. More guidance is given for each restraint type below.
Standard state correction¶
Since the restraint defines the bound complex, in order to report a standard state binding free energy, we must compute
the free energy of releasing the restraint into a volume V0 representing the standard state volume to achieve a
standard state concentration of 1 Molar. V0 is computed as the following:
where N_A is in Avogadro’s constant. This calculation results in \(V0 = 1660.53928 \unicode{xC5}^3\) where we treat V0
as a per mole quantity. More detail of how this free energy fits into the thermodynamic cycle can be found in
theory.
Restraint types¶
YANK currently supports several kinds of receptor-ligand restraints.
No restraints (null)¶
While it is possible to run a simulation without a restraint in explicit solvent—such that the noninteracting ligand must explore the entire simulation box—this is not possible in implicit solvent since the ligand can drift away into infinite space. Note that this is not recommended for explicit solvent, since there is a significant entropy bottleneck that must be overcome for the ligand to discover the binding site from the search space of the entire box.
Spherically symmetric restraints¶
Harmonic restraints (Harmonic)¶
A harmonic potential is imposed between the closest atom to the center of the receptor and the closest atom to the center of the ligand, given the initial geometry.
The equilibrium distance is zero, while the spring constant is selected such the potential reaches kT at one radius of gyration.
This allows the ligand to explore multiple binding sites—including internal sites—without drifting away from the receptor.
For implicit and explicit solvent calculations, harmonic restraints should be imposed at full strength and retained
throughout all alchemical states to define the bound complex.
Since the harmonic restraint is significant at the periphery of the receptor, it can lead to bias in estimates of
binding affinities on the surface of receptors.
The standard-state correction is computed via numerical quadrature.
Flat-bottom restraints (FlatBottom)¶
A variant of Harmonic where the restraint potential is zero in the central region and grows as a half-harmonic potential outside of this region.
A length scale sigma is computed from the median absolute distance from the central receptor atom to all atoms, multiplied by 1.4826.
The transition from flat to harmonic occurs at r0 = 2*sigma + 5*angstroms.
A spring constant of K = 0.6 * kilocalories_per_mole / angstroms**2 is used.
This restraint is described in detail in [17].
For implicit and explicit solvent calculations, flat-bottom restraints should be imposed at full strength and retained
throughout all alchemical states to define the bound complex.
The standard-state correction is computed via numerical quadrature.
Orientational restraints¶
Orientational restraints are used to confine the ligand to a single binding pose.
Warning
Because the ligand is highly restrained orientationally, the initial configuration should have the ligand well-placed in the binding site; errors in initial pose cannot be easily recovered from.
Boresch restraints (Boresch)¶
A common type of orientational restraints between receptor and ligand [18]. These restrain a distance, two angles, and three torsions in an attempt to keep the ligand in a specific relative binding pose. Default spring constants used in Table 1 of the original paper [18] are used, and a set of atoms is automatically chosen (three each in the ligand and receptor) to ensure that the distance (\(r_{aA0}\)) is within [1,4] Angstroms and the angles (\(\theta_{A0}\), \(\theta_{B0}\)) are several standard deviations away from 0 and \(\pi\).
Standard use of Boresch restraints is to turn on the restraints over several alchemical states and keep the restraints active while discharging followed by Lennard-Jones decoupling. This assumes the ligand is already effectively confined to its bound state even when the restraint is off such that imposing the restraint measures the free energy of additionally confining the bound ligand; if this is not the case, it could lead to problematic free energy estimates.
The standard state correction is computed by evaluating using a combination of numerical and analytical
one-dimensional integrals from Eq. 12 of [18].
Note that the analytical standard state correction described in Eq. 32 of [18] is inaccurate
(up to several kT) in certain regimes (near \(r_{aA0}\) and \(\theta_{A0}\), \(\theta_{B0}\) near
0 or \(\pi\)) and should be avoided.
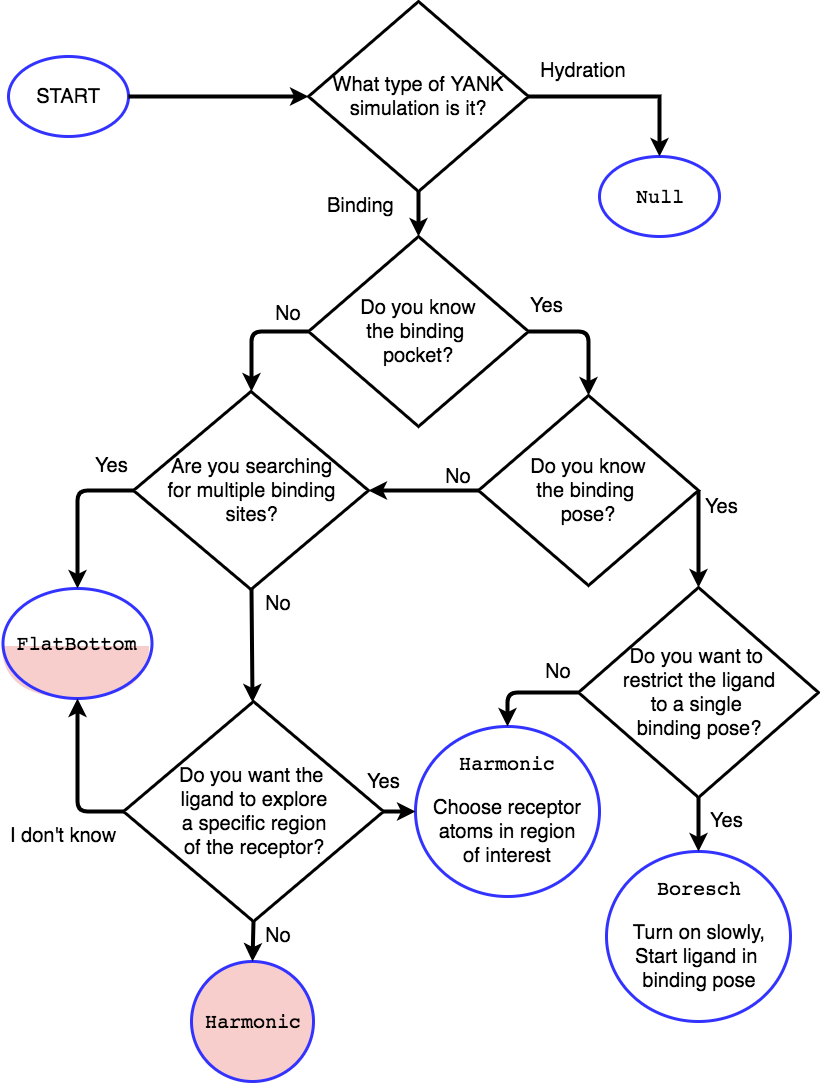
Restraint Selection Flowchart¶
Consult the following flowchart to assist in selecting the restraints and reference the following key additional guidance
Restraints are marked in end point circles
Unless stated, the restraints should always be fully coupled (NO
lambda_restraintsin the YAML file)Assume default parameters for restraints unless otherwise stated
Shaded entries are not recommended for use and may require user insight to be accurate, even if they are the “best option” for the choice of answers.
- The
Harmonicat the bottom restraints the ligand to the centroid of the receptor only, which may not be the binding site. Consider if this is really what you want to do. - The half-shaded
FlatBottomentry is not recommended if you don’t know what the ligand should do. You probably want the ligand to explore the whole receptor, but we cannot be sure if you reached this entry from the shaded side
- The
A
Nullentry indicates no restraints needed at all
Adding new restraints¶
YANK also makes it easy to add new types of restraints by subclassing the yank.restraints.ReceptorLigandRestraint class.
Simply subclassing this class (an abstract base class) and implementing the following methods will allow this restraint type to be specified via its classname.
__init__(self, topology, state, system, positions, receptor_atoms, ligand_atoms):get_restraint_force(self):get_standard_state_correction(self):
Alchemical protocol¶
Alchemical intermediate states are chosen to provide overlap along a one dimensional thermodynamic path for each phase of the simulation, ultimately making a complete thermodynamic cycle of binding/solvation.
A number of rules of thumb are followed when choosing what order to carry out alchemical intermediates, examples of which can be found in the Examples Documentation.
- Couple restraints before any other alchemical changes
- Decouple electrostatics first and separate from all other alchemical changes=
- Decouple Lennard-Jones interactions last.
- Always define the “fully coupled” state as the first index, 0 in Python, in the list of alchemical states (the state most closely representing the physically bound/fully solvated conditions)
- Always define the “fully decoupled/annihilated” state as the last index, -1 in Python, in the list of states.
Automatic Alchemical Protocol Selection¶
YANK supports automatically choosing the alchemical path instead of setting all the values by hand. The states are chosen such that the standard deviation of the difference of energies between states is roughly equal within some tolerance. States spaced equally by this metric should have better phase space overlap than states placed haphazardly, and should have better mixing in replica exchange.
The algorithm is as follows, given an upper and lower bound for a set of alchemical parameters:
- A short simulation is run at the upper bound of the parameter set.
- The potential energies of the simulated state are computed at a proposed state where the alchemical parameters are perturbed.
- The energies of the simulation are reweighted in the proposed state
- The standard deviation of the difference in energies between the simulated and proposed state is computed.
- If the standard deviation is within some tolerance around a target value, the proposed state is chosen and the process repeats with the proposed state as the new, simulated state.
- If the standard deviation is outside the tolerance, a new state is proposed is repeated without updating the simulated state.
- The cycle continues until the parameters’ lower bounds are reached.
Hamiltonian exchange with Gibbs sampling¶
The theory for this section is taken from a single source and summarized here [20]
Hamiltonian Replica Exchange (HREX) is carried out to improve sampling between different alchemical states. In the basic version of this scheme, a proposed swap of configurations between two alchemical states, i and j, made by comparing the energy of each configuration in each replica and swapping with a basic Metropolis criteria of
where \(x\) is the configuration of the subscripted states \(i\) or \(j\), and \(u\) is the reduced potential energy. We have added the second equality to improve readability. This scheme is typically carried out on neighboring states only.
YANK’s HREX scheme instead samples with Gibbs Sampling by attempting swaps between ALL \(K\) states simultaneously. However, instead of trying to directly sample the unnormalized probability distribution across all states and configurations, then performing an all-state-to-all-state swap, YANK draws from an approximate distribution by attempting \(K^5\) swaps between uniformly chosen pairs of states. The acceptance criteria for each swap is the same as above, but you can show with this state selection scheme and number of swap attempts, that you will effectively draw from the correct distribution without too much computational overhead [20]. This speeds up mixing and reduces the total number of samples you need to get uncorrelated samples.
Markov chain Monte Carlo¶
YANK implements a replica exchange scheme with Gibbs sampling [20] to sample multiple thermodynamic states in a manner that improves mixing of the overall Markov chain. In between replica exchange attempts, YANK uses compositions of Markov chain Monte Carlo (MCMC) moves from the openmmtools.mcmc module to sample from the equilibrium distribution at each thermodynamic states. Each MCMC move is treated as a single, independent, MCMC move carried out in sequence so that samples are drawn from the equilibrium distribution at each step. Should one move be rejected, the other moves will still be carried out.
Generalized Hybrid Monte Carlo¶
Generalized hybrid Monte Carlo (GHMC) moves are MC moves where the proposed move is generated by some molecular dynamics algorithm, and then weighted by generalized ensemble being sampled. In YANK, we generate samples with a psuedo-GHMC move through Langevin dynamics, but do not actually make an MC evaluation. Velocities are drawn from the Maxwell-Boltzmann distribution at the start of the move, then MD is propagated through the stochastic Langevin dynamics integration. We assume the discretization error is negligible, but the generation of the correct distribution is only truly exact in the limit of infinitely small timestep.
See the OpenMMTools documentation on Langevin Dynamics Moves for more information.
Metropolis Monte Carlo displacement and rotation moves¶
Ligands often are trapped by kinetic barriers and steric clashes, limiting their configurational space. Hamiltonian replica exchange allows the ligand to escape these traps by swapping to a new the thermodynamic state, but the swap may occur with a state where the ligand is nowhere near the same volume of space.
YANK enhances sampling by proposing MC displacement and rotation moves on the ligand without leaving the same state. These MC moves are separate actions, and evaluated as independent moves.
The MC Rotation move is proposed by rotating all particles in the ligand by a uniform normalized quaternion 4-vector [21]. See the OpenMMTools MCRotation docs for more information.
The MC Displacement proposes a move where the ligand atoms are translated in each Cartesian dimension by uniformly drawn random number on \([0,1]\) domain, then scaled by a small perturbation distance, \(\sigma\). The final proposed position is then evaluated as the MC move. The ligand in this case is translated as a singular unit, so each particle is translated by the same distance in each direction.
Ligand rotation and displacements moves are disabled for the orientational Boresch restraints. This class of MCMC move under the orientational restraints will almost always be rejected so they are not enabled to reduce computational time.
Automated equilibration detection¶
In principle, we don’t need to discard initial “unequilibrated” data; the estimate over a very long trajectory will converge to the correct free energy estimate no matter what, we simply need to run long enough. Some MCMC practitioners, like Geyer, feel strongly enough about this to throw up a webpage in defense of this position.
In practice, if the initial conditions are very atypical of equilibrium (which is often the case in molecular simulation, especially after energy minimization), it helps a great deal to discard an initial part of the simulation to equilibration. But how much? How do we decide? YANK chooses an automatic equilibrium detection scheme based on the following articles: [22] [20] [23]
Determining a timeseries to analyze in a replica-exchange simulation¶
For a standard molecular dynamics simulation producing a trajectory \(x_t\), it’s reasonably straightforward to decide approximately how much to discard if human intervention is allowed. Simply look at some property \(A_t = A(x_t)\) over the course of the simulation. This property should ideally be one that we know has some slow behavior that may affect the quantities we are interested in computing and find the point where \(A_t\) seems to have “settled in” to typical equilibrium behavior. \(A(x)\) is a good choice if we’re interested in the expectation \(\left\langle A \right\rangle\).
If we’re interested in a free energy, which is computed from the potential energy differences, let’s suppose the potential energy \(U(x)\) may be a good quantity to examine.
In replica-exchange simulation, there are K replicas that execute nonphysical walks on many potential energy functions \(U_k(x)\). The multiple states call into question what observable should be examined. Let’s work by analogy. In a single simulation, we would plot some quantity related to the potential energy \(U(x)\), or its reduced version \(u(x) = \beta U(x)\). This is actually the negative logarithm of the probability density \(\pi(x)\) sampled, up to an additive constant:
For a replica-exchange simulation, the sampler state is given by the pair \((X,S)\), where \(X = \{x_1, x_2, \ldots, x_K \}\) are the replica configurations and \(S = \{s_1, s_2, \ldots, s_K\}\) is the vector of state index permutations associated with the replicas. The total probability sampled is
where the pseudoenergy \(u_*(X)\) for the replica-exchange simulation is defined as
That is, \(u_*(X)\) is the sum of the reduced potential energies of each replica configuration at the current thermodynamic state it is visiting.
Identifying equilibration and production regions in a replica-exchange simulations¶
YANK automatically determines an optimal partitioning between the initial equilibration phase of the simulation (which is discarded) and the production phase of the simulation (which is analyzed to estimate free energies).
We first define a some terminology. We start with finite count of samples \(t \in [1,T]\) where t is the individual sample index and T is the total number of samples. For a given observable \(A\) drawn from a configuration \(x\), indexed by \(t\), let \(a_t \equiv A(x_t)\).
In an infinite set of samples from the simulations, we expect the bias from the initial transiant, not fully-equilibrated, samples to be negligible. However, in a finite simulation, this is not necessarily the case. We construct an estimator for the expectation of the observable
where we also assume that there is some correlation time between each observable \(\tau\). We can also define a metric of statistical efficiency by \(g \equiv 1 + 2\tau\). If we compute the correlation time with the non-equilibrated data, then the correlation times will be much longer than they should be, resulting in many more samples being discarded due to correlation. As such, we assume that we can reduce the bias in the series of observables by discarding some initial set of samples, \(t_0 \geq t\) such that the expectation then becomes
Because we can conclude the bias will only increase the correlation time, lowering the total number of samples used in analysis, we define the metric of both equilibration and correlation as the \(t_0\) which maximizes the total number of effective samples leftover after discarding from equilibration and correlation. This metric is computed by
where \(g_{t_0}\) is the statistical efficiency of the timeseries with all samples before \(t_0\) discarded as the equilibration. We then look at each index of \(t\) proposing it as \(t_0\) until we find the one which maximizes \(N_{\text{eff}}\). \(\tau\) is computed from the following equations [23]:
where \(t'\) is the proposed \(t_0\), \(a_n\) is the observable series on indices \([t',T]\), and \(a_{n+t}\) is the observable series on indices \([t'+t,T]\). At the maximized \(N_{\text{eff}}\), all samples before \(t_0\) are considered “unequilibrated” and discarded, and decorrelated samples are drawn on an interval of \(g_{t_0}\) from the remaining series.
This is all implemented in the pymbar module: timeseries
Analysis with MBAR¶
Free energies and other observables are computed with the Multistate Bennet Acceptance Ratio (MBAR) implemented in
the pymbar package [22]. MBAR requires the energy of each sampled configuration evaluated at every
state we wish to compute the free energy at, and then the number of samples drawn from each state. From there, the
free energy of each state is estimates through the self-consistent equation of
where \(f\) is the dimensionless free energy estimate of state i (in units of kT), \(K\) is the number of sampled states, \(u\) is the dimensionless potential energy, \(N\) is the number of samples from a given state, and \(x\) is the sampled configuration. Because this requires a self-consistent, it is an underspecified problem as presented. However, we really only care about differences in free energies between states, so one state is chosen as the reference, so \(f_0 = 0\). This equation is also not conditioned on state \(i\) being part of the sampled states \(K\), allowing estimation of the free energy at any thermodynamic state such as the unsampled states with expanded cutoffs that YANK supports.
Automated convergence detection¶
YANK has the ability to run a simulation until the free energy difference in a phase reaches a user-specified target
uncertainty.
If this option is set, either through the yaml options or
the ReplicaExchange API, then each phase will be simulated until either the
error free energy difference reaches the target, or the maximum number of iterations has been reached.
Free energy error alone is a helpful, but not necessarily sufficient metric of convergence, and other measures will be implemented in future releases to help better gauge simulation convergence.
Simulation health report¶
YANK’s analysis module can also create Jupyter Notebooks which help provide visual information to determine the quality of the simulation. An example notebook can be found here. This notebook takes the analysis ideas from the previous section and puts them into chart format. All of the information shown in this report is also part of the main analysis suite run from command line, but can often get lost as pure text output.
The first block of the notebook plots the timeseries, autocorrelation time, and effective number of samples detailed in the previous sections for each phase. The first block also breaks down how many samples are lost to equilibration and decorrelation, and how many samples are left over for analysis.
The second block computes the mixing statistics between each replica. This is done empirically based on number of times a replica transitions from alchemical state \(i\) to state \(j\) in a single iteration. Because the overall chain must obey detailed balance, we count each transition as contributing 0.5 counts toward the \(i \rightarrow j\) direction and 0.5 in the reverse. This has the advantage of ensuring that the eigenvalues of the resulting transition matrix among alchemical states are purely real.
The second block also computes the Perron (subdominant/second) eigenvalue as a measure of how well mixed all the replicas are. If the subdominant eigenvalue would have been unity, then the chain would be decomposable, meaning that it completely separated into two separate sets of alchemical states that did not mix. This would have been an indication of poor phase space overlap between some alchemical states. If the configuration \(x\) sampling is infinitely fast so that \(x\) can be considered to be at equilibrium given the instantaneous permutation \(S\) of alchemical state assignments, the subdominant eigenvalue \(\lambda_2 \in [0,1]\) gives an estimate of the mixing time of the overall \((X,S)\) chain:
\(\tau_{\lambda}\) is then the estimate for how many iterations must elapse before the collection of replicas fully mix once. The closer this value is to unity (1), the better.